Lab 9: Interactions between continuous variables
PSYC 7804 - Regression with Lab
By the way, Interaction or Moderation?
Interaction and moderation are the same exact thing.
I prefer the term interaction to avoid confusion with the term mediation, which has absolutely nothing to do with anything discussed in this Lab. That being said …
When hypothesizing interaction effects, it is useful to make a distinction between a focal predictor and a moderator.
Interactions are usually represented with the diagrams on the right. the variable pointing directly to \(Y\) is considered the focal predictor, while the variable pointing to the line is considered the moderator.
The two representation on the right are equivalent. However, depending on your hypotheses it may make more practical sense to conceptualize one variables as the focal predictor and the other as the moderator.

Mean Centering Graphically
Changing the mean of a variable simply means shifting it along the x-axis. For example, if we plot the density of the uncentered and centered attend variable:
Plot Code
grade_fin %>%
ggplot(aes(x = attend)) +
geom_density(col = "red") +
geom_density(aes(x = attend_cnt), col = "blue") +
xlim(-30, 40) +
xlab("Centerd and Uncentered Distribution of `attend`")
- The red distribution is the original uncentered variable.
- the blue distribution is the mean centered variable.
Linear Transformations
Centering and standardizing are known as linear transformations. The “linear” comes from the fact that all these transformations do is shift all the data along a line. You can see that from the graph on the left. These transformations have no effect on the results of statistical analyses, but can make interpretation easier.
Plotting Simple Slopes
The code below plots the simple slopes at different values of the moderator:
interact_plot(reg_int_cnt,
modx = "priGPA_cnt",
pred = "attend_cnt")You can also think of the slopes in this plot as a snapshot of the direction of the regression plane at a specific value of the moderator!

Plotting Simple Slopes
We can also specify values of the moderator manually:
interact_plot(reg_int_cnt,
modx = "priGPA_cnt",
pred = "attend_cnt",
modx.values = c(-4, 3, 4))
The johnson-neyman Plot 😱
Instead the simple slopes, we can visualize how the slope of the focal predictor changes as the moderator changes:
johnson_neyman(reg_int_cnt,
modx = "priGPA_cnt",
pred = "attend_cnt")- x-axis: the value of the moderator.
- y-axis: the value of the slope of the focal predictor (make sure this makes sense to you!)
The blue band means that the slope of the focal predictor is significant at the value of the moderator.
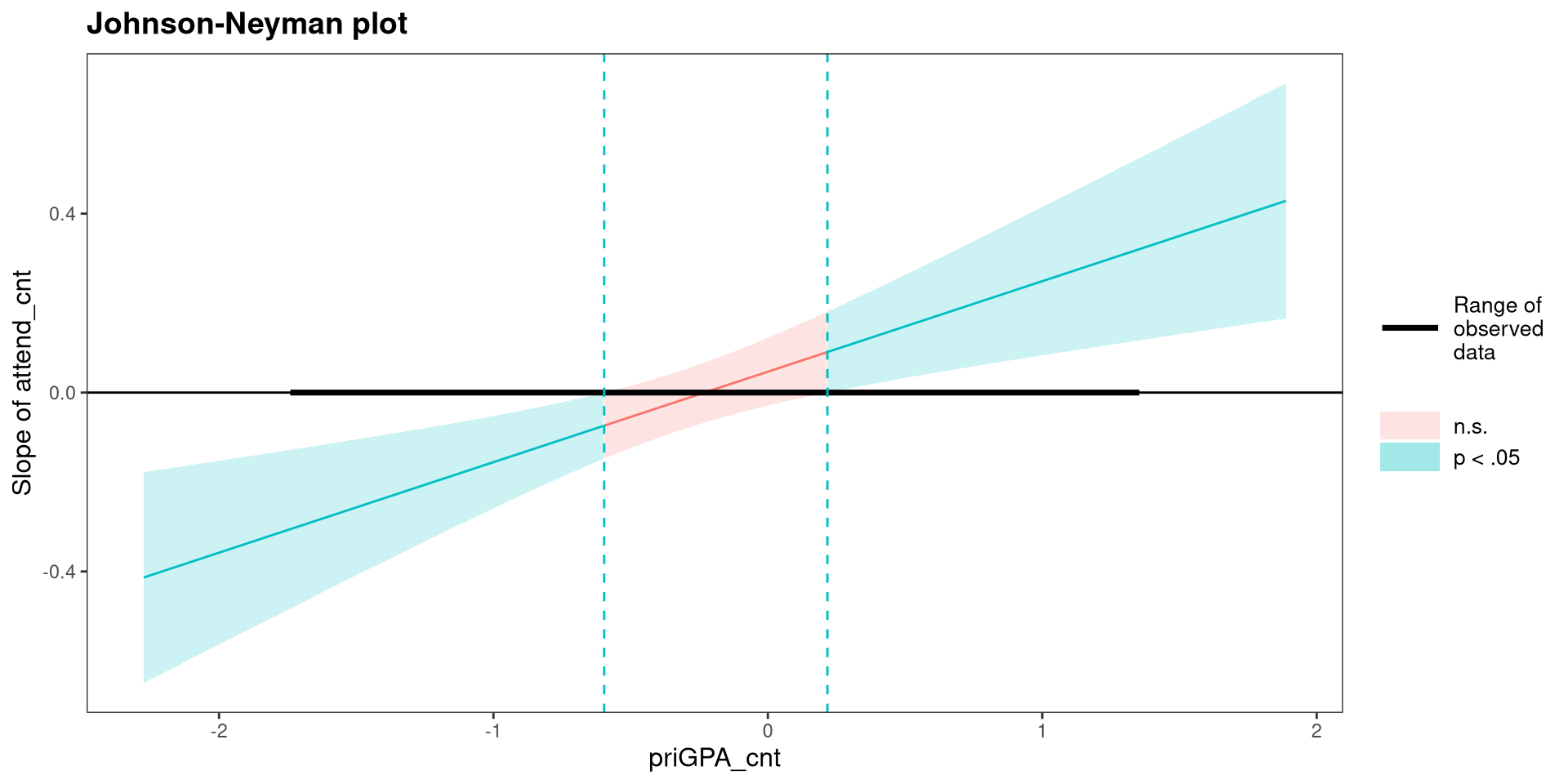
Advice: If you are presenting your research and interactions are involved…I would use simple slopes instead of a Johnson-Neyman plot. Why? It’s an absolute truth about the universe that Johnson-Neyman plots are confusing 🤷 keep it simple.